September 9, 2024
6 min read
Efficient Vision-Language-Action Models
Paweł Budzianowski
Vision-language models (VLMs) offer a fantastic opportunity to address a fundamental challenge in robotics: the scarcity of data. Models like OpenVLA have demonstrated the potential of these approaches. However, deploying an 8B parameter model on edge devices presents significant challenges. In this post, we present a path to significantly improve the inference speed of vision-language-action (VLA) models while maintaining two core requirements:
- Adaptation of VLMs while preserving their encoding representation power.
- High inference speed on edge devices (e.g., Jetson Nano) running at 30–50 Hz.
Our proposed Edge VLA (EVLA) model satisfies both requirements, enabling easier deployment on edge devices and democratizing access for everyone. We share our early pre-training results, model and accompanying Github repository.
Current challenges
Models like OpenVLA require substantial computational resources, making deployment and testing on edge devices challenging. Just to host the model, 16GB VRAM is needed, necessitating devices like the Jetson AGX, which costs over $2,000. This high barrier to entry prevents widespread adoption and experimentation.
Even with high-end hardware, these models are often too slow for practical manipulation tasks, running at only 1–2 Hz without significant optimization and quantization efforts. This limitation hinders real-time applications and research progress. While quantization methods and hardware-specific kernels can accelerate the model, these techniques alone may not yield the potential 10x improvements we seek.
Our Approach: Balancing Efficiency and Performance
Joint Control vs. Autoregressive Prediction
Large language models are trained using a causal mask, which aligns with the natural way humans write text. However, when predicting end-effector positions or humanoid joint poses, it’s worth questioning whether such a restrictive structure is necessary. We demonstrate that autoregressive requirements are not essential for predicting end-effector positions. In our proposed setup, the pre-trained LLM outputs the end effector position at once. We have trained different models to validate that this change of prediction setup does not lower the encoding capabilities for both small and large variants. By adopting a joint control approach, we increase inference speed by a factor of 6. This advancement is crucial for real-time robotic control on edge devices.
Small Language Models (SLMs)
Secondly, the recent advancements in small language models (such as Phi, Gemma and many more) show the potential in making LLMs much more effective than early versions. These models, trained on a large number of tokens, effectively achieve performance comparable to larger models while requiring significantly less computational resources thanks to scaling laws. We have tested multiple different small foundation models achieving very comparable performance in the pre-training runs proving that we can do more with less greatly lowering the requirements for the hardware.
Putting It All Together:
We have combined above two ideas to achieve required architectural improvements. First, we trained a VLM resulting in our base EVLA model. Key components include:
- Qwen2 with 0.5B parameters for language processing.
- A two-part visual encoder using pretrained SigLIP and DinoV2 models, following the original OpenVLA recipe.
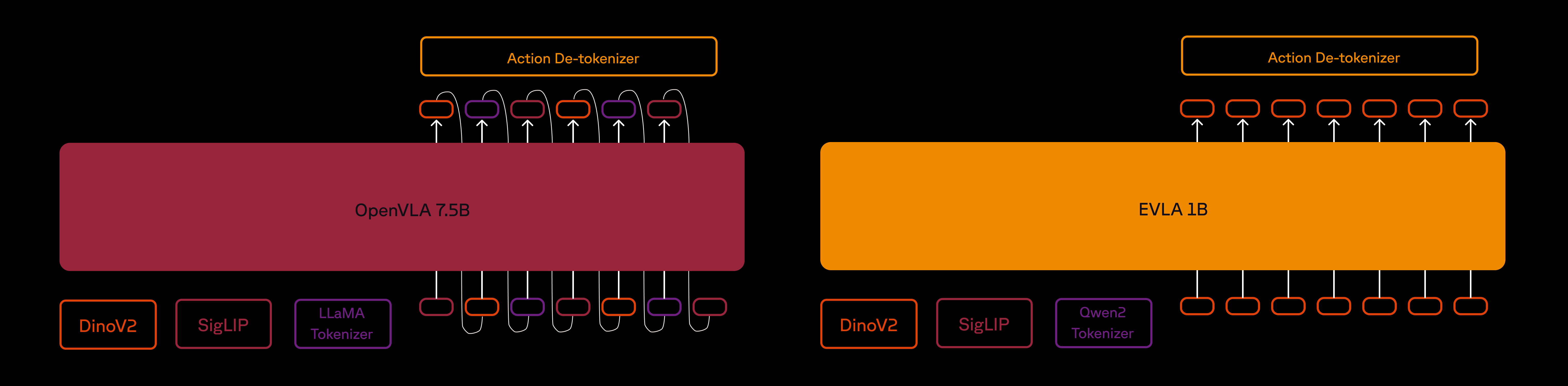
The comparison of generation logic between OpenVLA and EVLA. The pretraining phase is identical for both models. In phase two, the EVLA LLM is being retrained to generate end-effector position in an autoregressive fashion.
We adopt a standard approach by training a projection layer that maps the visual representation to the language model’s token space. Our pre-training dataset comprises of two subsets: 1) a 558K sample mixture of examples sourced from various captioning datasets, and 2) a 665K set of multimodal instruction-tuning examples composed of synthetic data. In total, the pre-training dataset contains 1.2M text-image pairs.
Training results
Having pretrained the foundation VLM, we explore the minimal setup to verify the strategy. We initially trained on the Bridge subset using one node with 8 GPUs. This quick experiment validated that our model could achieve similar performance compared to original 7B OpenVLA.
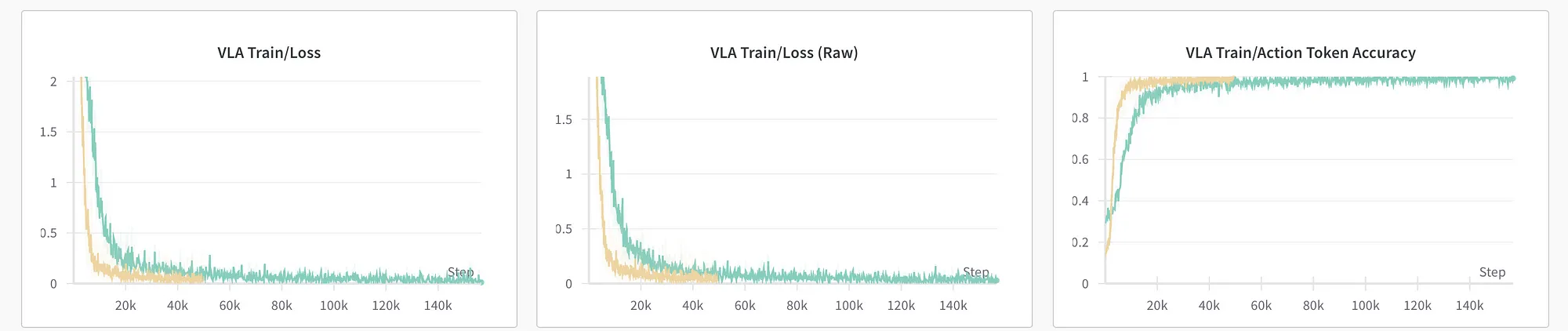
OpenVLA (yellow) versus EVLA (green) on the Bridge dataset smoothed with time-weighted EMA.
We then scaled up the training to use our full cluster to evaluate performance on the OXE dataset. While EVLA trains more slowly than its larger counterpart due to the dataset’s size, the training pass is 7x faster and allows for much larger batch sizes, effectively compensating for the slower training efficiency.
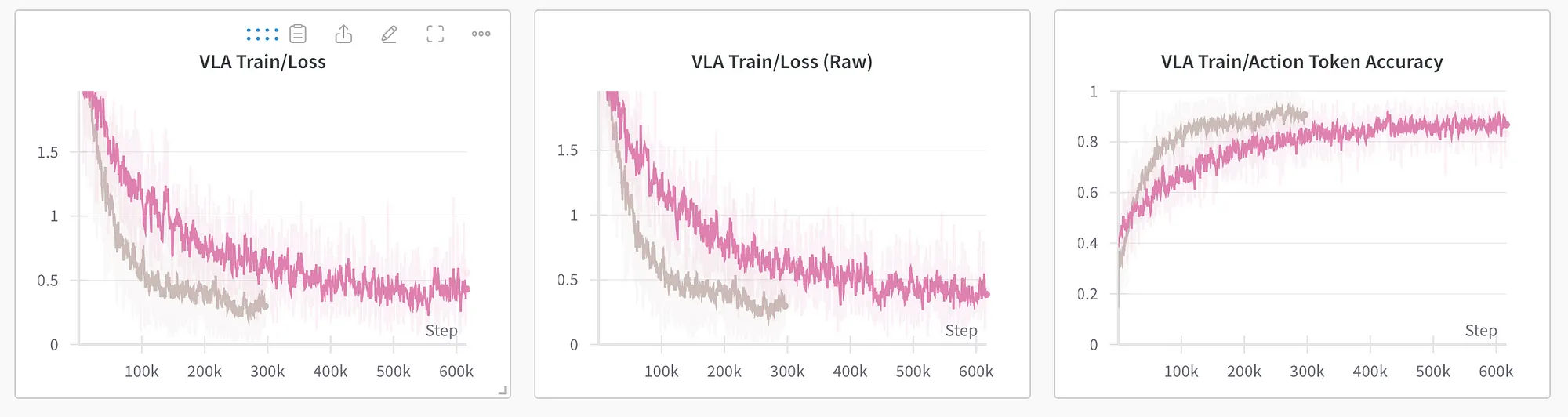
OpenVLA (grey) versus EVLA (pink) on the full OXE dataset smoothed with time-weighted EMA.
These early runs shows that adapting efficient and smaller LLMs to non-autoregressive objectives achieves similar training performance than the original larger counterparts.
Efficiency Gains
Employing VLM for predicting end-effector position or whole body joint pose requires much faster inference speed than currently available LLM approaches. EVLA achieves both high-speed inference time but also lowers the memory requirements allowing to use cheaper hardware.
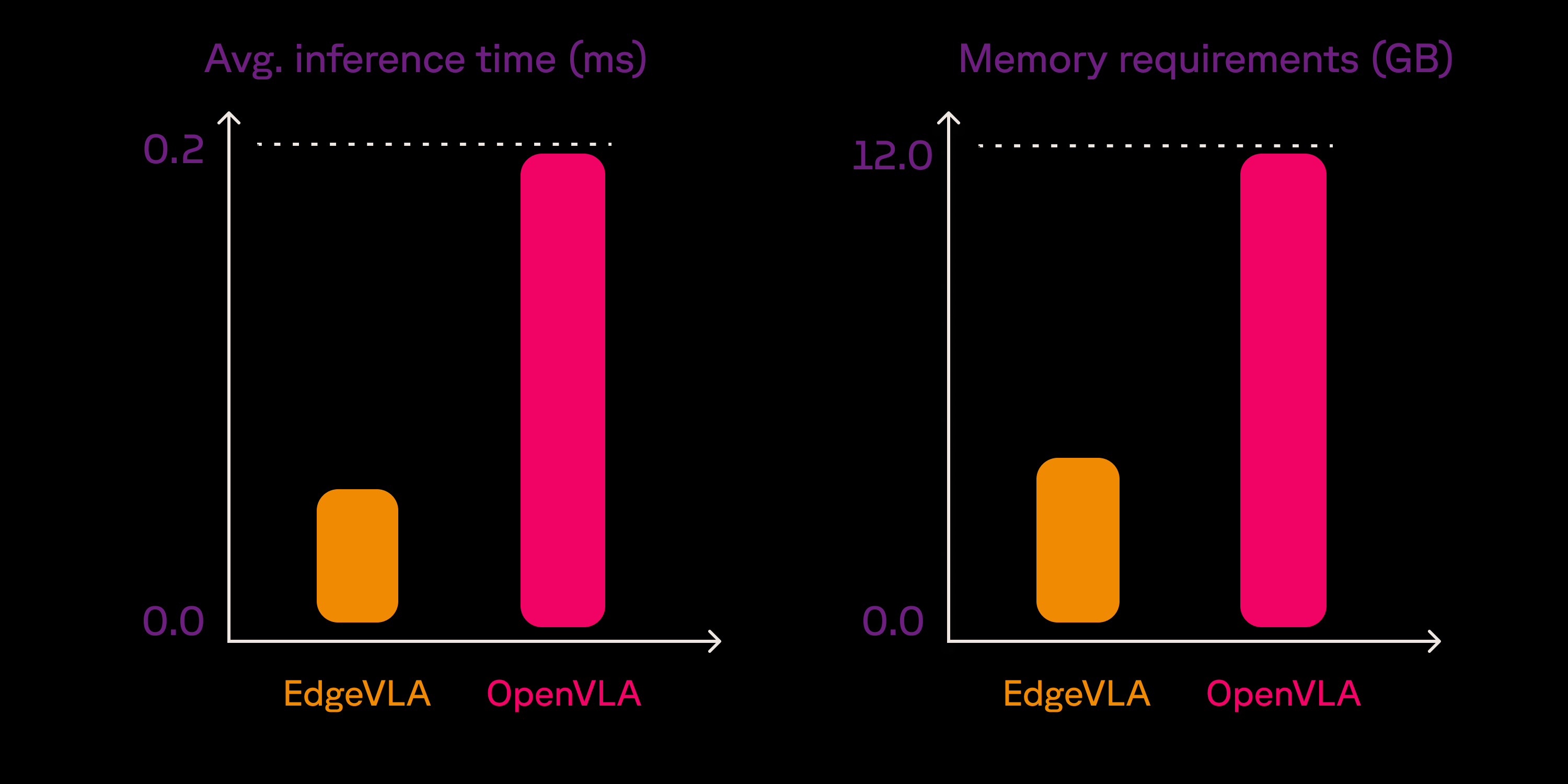
Evaluation performed on A100–40GB.
By using a smaller VLM and optimizing our architecture, you can achieve as expected significant inference speed improvements. It is worth noting that OpenVLA uses flash_attention2, while EVLA is evaluated in the eager mode. Advances in flexible and efficient attention mechanisms, such as those discussed in the PyTorch blog on FlexAttention, are expected to push these numbers even lower in the near future. This size of the model also offers a potential to be deployed on CPU architectures.
Sharing with the community
We will be updating you with performance finetuned on our new embodiments but you can already test it yourself with any manipulator or humanoid of your choice. We’re committed to advancing the field of embodied AI collectively. That is why, we’re sharing our early model definitions and training code with the community. By making these resources accessible, we hope to inspire further innovations in VLA models for embodied AI and lower the barriers to entry for researchers and enthusiasts alike.
We will also soon share more artifacts which allow direct deployment on edge with Jetson Nano and AGX. Stay tuned!